| Model | AUC | ACC | BAL_AP | EER | AP |
|---|---|---|---|---|---|
| Lightning | 0.7566 | 0.7720 | 0.7340 | 0.3037 | 0.1189 |
| Gend | 0.5869 | 0.8299 | 0.5592 | 0.4332 | 0.0409 |
| Xception | 0.5601 | 0.7849 | 0.5536 | 0.4574 | 0.0389 |
| Prodet | 0.5544 | 0.1400 | 0.5525 | 0.4601 | 0.0366 |
| Effort | 0.5516 | 0.5338 | 0.5361 | 0.4639 | 0.0342 |
| F3Net | 0.5300 | 0.3373 | 0.5199 | 0.4809 | 0.0320 |
| UCF | 0.5247 | 0.2727 | 0.5136 | 0.4855 | 0.0309 |
| ForAda | 0.5178 | 0.6810 | 0.5154 | 0.4857 | 0.0351 |
| Core | 0.5153 | 0.6503 | 0.5103 | 0.4805 | 0.0314 |
Less Data, Less Learning
The Additive Fallacy & Four-fold Paradox
Current pre-trained models leverage billions of images to converge through iterative optimization.
Previously, LoRA-based approaches were the predominant PEFT methods, implementing low-rank adaptation through an additive logic (Han et al. 2024). However, in my view, those could lead to model’s pre-trained knowledge being ‘hijacked’ by a disproportionately small amount of data, causing a domain shift away from the original weight distribution.
In fact, I argue that LoRA(Hu et al. 2022) is inherently trapped in a four-fold paradox:
1. From the perspective of data scale: If the data volume is sufficiently large, LoRA becomes redundant compared to full fine-tuning; if the data volume is small, it inevitably introduces severe bias and shortcut learning.
2. From the perspective of domain gap: If the target domain is close to the pre-training domain, LoRA’s low-rank updates tend to hijack and distort the optimal weight manifold, obliterating the model’s zero-shot generalization capabilities; conversely, if the domain gap is significantly large, LoRA fundamentally fails to exploit the immense parametric dividends of the base model.
We evaluated a series of SOTA architectures spanning from 2019 to 2026. This lineup tracks the field’s evolution, including Xception (Rossler et al. 2019), F3Net (Qian et al. 2020), Core (Ni et al. 2022), UCF (Yan et al. 2023), ProDet (Cheng et al. 2024), ForAda (Cui et al. 2025), Effort (Yan et al. 2025), GenD (Yermakov et al. 2026), and our proposed Lightning. The average AUC performance of these models on OpenFake(Livernoche et al. 2025)—a large-scale dataset comprising several in-the-wild text-to-image subsets—is summarized as follows.
Empirical Observation: Catastrophic Forgetting
As shown in Table 1, all iterative methods suffered from severe catastrophic forgetting when zero-shot transferring to OpenFake (after being trained on FaceForensics++).
In particular, PEFT methods based on LoRA (such as Effort, ForAda, and GenD)—which were originally designed to preserve pre-trained knowledge—have paradoxically collapsed, losing almost all the capability inherited from the pre-trained CLIP(Radford et al. 2021).
OpenFake consists of images generated by text-to-image models, which is theoretically CLIP’s forte. However, while Lightning (also based on CLIP) achieved an AUC of 0.76, other methods failed to even exceed 0.6. This stark contrast perfectly corresponds to the hypothesis we proposed earlier:
“If the target domain is close to the pre-training domain, LoRA’s low-rank updates tend to hijack and distort the optimal weight manifold, obliterating the model’s zero-shot generalization capabilities.”
Hypothesis: The Delta Steering Vector
It is well known that models with more parameters are more prone to overfitting, which is precisely why LoRA has frequently achieved success by reducing the number of trainable parameters.
Interestingly, while numerous models are still struggling to compress parameters within the LoRA framework, Lightning proposes a gradient-free closed-form solution. By having absolutely zero trainable parameters, Lightning inherently minimizes the risk of domain overfitting.
Fundamentally, generative artifact detection is not a representation learning problem; it is a Signal-to-Noise Ratio (SNR) problem.
In pre-trained Vision Transformers like CLIP, massive semantic features dominate the representation. For artifact detection, these semantics act as overwhelming background “noise” if not properly isolated. Iterative methods attempt to add parameters to navigate this noise, inevitably confusing the image content with the forensic signal (leading to overfitting).
But why navigate the noise when you can orthogonally decouple it? Instead of discarding the semantic features, we use them as a stable “Semantic Anchor” defining the authentic manifold. We then project the features into an orthogonal subspace to isolate the subtle forensic artifacts.
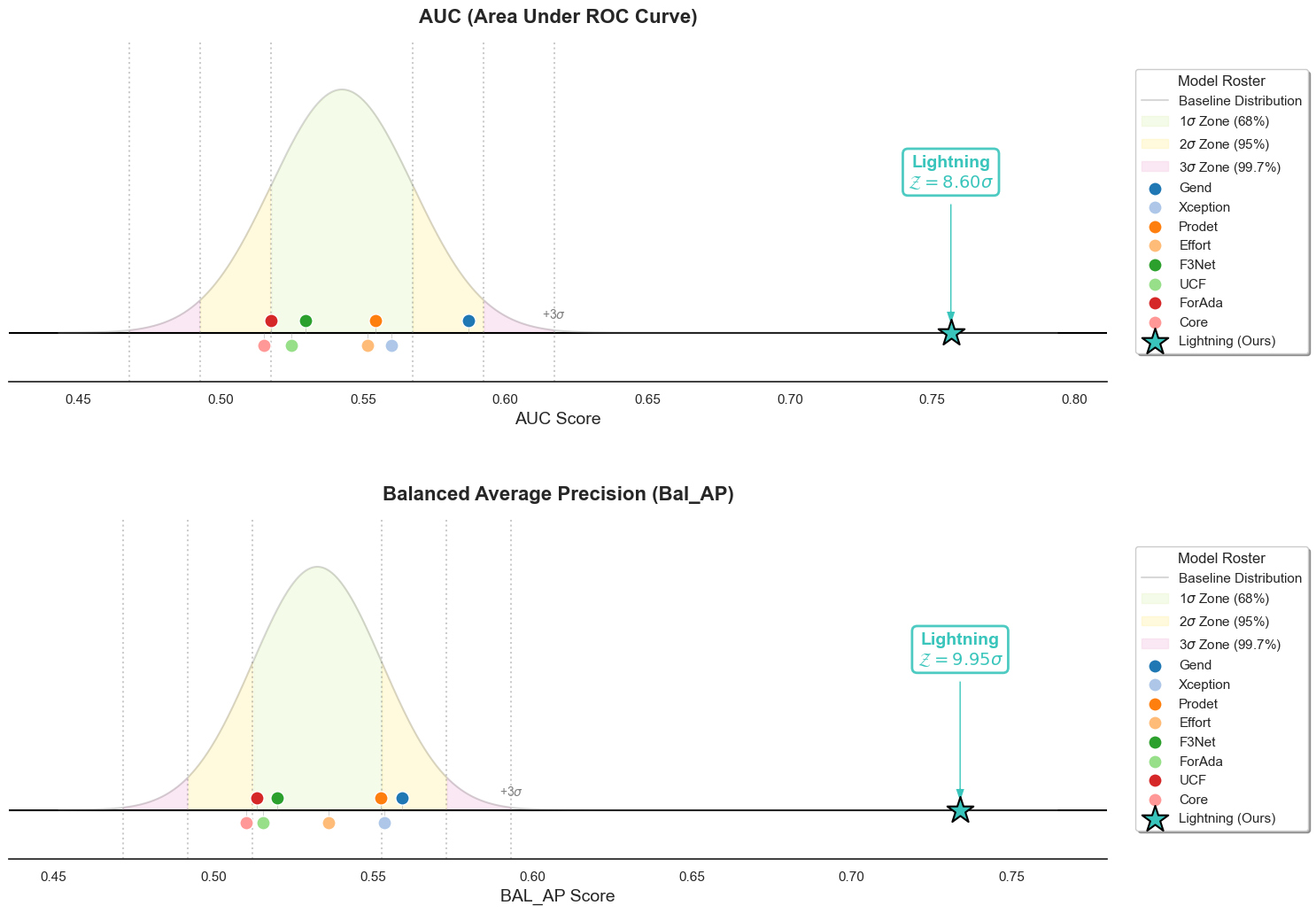
Statistical Note on Paradigm Modeling: While performance metrics (like AUC) are bounded manifolds and specific model architectures are not strictly independent and identically distributed (i.i.d.), fitting a Gaussian distribution over the baseline population serves as a powerful empirical heuristic. It is not intended as a strict parametric hypothesis test, but rather to quantify the “gravitational pull” of the current iterative paradigm. Escaping this pull by \(8.56\sigma\) visually and mathematically defines a paradigm shift.
While all prior methods remain trapped within the \(3\sigma\) boundary, our model achieves an unprecedented leap—outperforming the baseline by 8.56 standard deviations in AUC and nearly 10 standard deviations in Balanced AP, effectively redefining the statistical limits of GenAI Detection.
Appendix: Detailed SOTA Breakdown
| Model | aurora-20-1-25 | chroma | dalle-3 | flux-1.1-pro | flux-amateursnapshotphotos | flux-mvc5000 | flux-realism | flux.1-dev | flux.1-schnell | frames-23-1-25 | gpt-image-1 | grok-2-image-1212 | halfmoon-4-4-25 | hidream-i1-full | ideogram-2.0 | ideogram-3.0 | imagen-3.0-002 | imagen-4.0 | lumina-17-2-25 | midjourney-6 | midjourney-7 | mystic | recraft-v2 | recraft-v3 | sd-1.5 | sd-1.5-dreamshaper | sd-1.5-epicdream | sd-2.1 | sd-3.5 | sdxl | sdxl-epic-realism | sdxl-juggernaut | sdxl-realvis-v5 | sdxl-touchofrealism | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lightning | 0.7361 | 0.8595 | 0.7207 | 0.6229 | 0.7092 | 0.4007 | 0.8152 | 0.8315 | 0.8406 | 0.8556 | 0.6419 | 0.5790 | 0.8498 | 0.7828 | 0.8624 | 0.8147 | 0.5963 | 0.6449 | 0.7666 | 0.7168 | 0.8785 | 0.7737 | 0.6288 | 0.7742 | 0.7955 | 0.7802 | 0.7925 | 0.8985 | 0.8455 | 0.8870 | 0.6793 | 0.7205 | 0.7762 | 0.8470 | 0.7566 |
| Gend | 0.6261 | 0.5979 | 0.6639 | 0.4683 | 0.4533 | 0.3723 | 0.4718 | 0.4745 | 0.5556 | 0.6292 | 0.5486 | 0.4783 | 0.6486 | 0.5421 | 0.6165 | 0.5666 | 0.5034 | 0.5501 | 0.6329 | 0.5313 | 0.6283 | 0.5360 | 0.5296 | 0.5432 | 0.7978 | 0.7294 | 0.6471 | 0.8343 | 0.5912 | 0.7105 | 0.6046 | 0.5685 | 0.6390 | 0.6654 | 0.5869 |
| Xception | 0.5394 | 0.6375 | 0.5648 | 0.5629 | 0.5751 | 0.5146 | 0.5289 | 0.5631 | 0.5974 | 0.5647 | 0.5347 | 0.4525 | 0.6316 | 0.6615 | 0.5493 | 0.5351 | 0.6081 | 0.6479 | 0.7676 | 0.5360 | 0.5985 | 0.5394 | 0.6047 | 0.5730 | 0.5614 | 0.3374 | 0.4546 | 0.5898 | 0.6355 | 0.5142 | 0.5339 | 0.5827 | 0.4762 | 0.4701 | 0.5601 |
| Prodet | 0.7088 | 0.5848 | 0.4622 | 0.5842 | 0.5855 | 0.5589 | 0.5842 | 0.6085 | 0.6060 | 0.6326 | 0.4139 | 0.6328 | 0.6684 | 0.5842 | 0.5633 | 0.5206 | 0.4675 | 0.5232 | 0.6783 | 0.5390 | 0.6600 | 0.5345 | 0.5585 | 0.6247 | 0.5427 | 0.4110 | 0.4932 | 0.5342 | 0.5378 | 0.5657 | 0.4659 | 0.4607 | 0.3995 | 0.5552 | 0.5544 |
| Effort | 0.6385 | 0.5336 | 0.4316 | 0.5152 | 0.5184 | 0.4320 | 0.4678 | 0.4397 | 0.5148 | 0.6349 | 0.5189 | 0.4793 | 0.6025 | 0.4606 | 0.6279 | 0.5096 | 0.5236 | 0.4936 | 0.6145 | 0.5181 | 0.5872 | 0.5739 | 0.6195 | 0.5803 | 0.7177 | 0.6606 | 0.5538 | 0.7389 | 0.5207 | 0.6353 | 0.5142 | 0.5023 | 0.5135 | 0.5623 | 0.5516 |
| F3Net | 0.5905 | 0.5853 | 0.4631 | 0.5329 | 0.6178 | 0.5342 | 0.5668 | 0.5849 | 0.5664 | 0.5754 | 0.4963 | 0.5048 | 0.6312 | 0.5909 | 0.4362 | 0.4740 | 0.5269 | 0.5489 | 0.7350 | 0.4455 | 0.5552 | 0.5619 | 0.5879 | 0.5752 | 0.3478 | 0.3255 | 0.4929 | 0.4918 | 0.5880 | 0.4733 | 0.5343 | 0.5373 | 0.4275 | 0.5129 | 0.5300 |
| UCF | 0.4950 | 0.5961 | 0.4177 | 0.5633 | 0.6270 | 0.5508 | 0.5803 | 0.6089 | 0.5988 | 0.5994 | 0.4717 | 0.4294 | 0.6469 | 0.6264 | 0.4786 | 0.4741 | 0.5374 | 0.5664 | 0.6900 | 0.4543 | 0.4753 | 0.5798 | 0.5579 | 0.5226 | 0.4214 | 0.2666 | 0.4608 | 0.4978 | 0.5949 | 0.5227 | 0.4757 | 0.5710 | 0.3919 | 0.4890 | 0.5247 |
| ForAda | 0.4661 | 0.5843 | 0.3930 | 0.4740 | 0.5056 | 0.4163 | 0.4675 | 0.4484 | 0.5376 | 0.5417 | 0.4950 | 0.4303 | 0.5291 | 0.4929 | 0.5015 | 0.4950 | 0.4853 | 0.4943 | 0.6004 | 0.4237 | 0.5054 | 0.5546 | 0.4609 | 0.4833 | 0.7171 | 0.6058 | 0.5066 | 0.7737 | 0.5176 | 0.6307 | 0.5094 | 0.4972 | 0.5119 | 0.5490 | 0.5178 |
| Core | 0.5240 | 0.5493 | 0.4546 | 0.4947 | 0.6105 | 0.5037 | 0.6150 | 0.6211 | 0.5642 | 0.5052 | 0.5150 | 0.5267 | 0.6085 | 0.5522 | 0.4620 | 0.5268 | 0.4677 | 0.5101 | 0.6844 | 0.4053 | 0.5783 | 0.6219 | 0.4799 | 0.5167 | 0.3117 | 0.4261 | 0.4832 | 0.4503 | 0.5235 | 0.5136 | 0.4810 | 0.4927 | 0.3996 | 0.5414 | 0.5153 |
References
Cheng, Jikang, Zhiyuan Yan, Ying Zhang, Yuhao Luo, Zhongyuan Wang, and Chen Li. 2024. “Can We Leave Deepfake Data Behind in Training Deepfake Detector?” Advances in Neural Information Processing Systems 37: 21979–98.
Cui, Xinjie, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. 2025. “Forensics Adapter: Adapting Clip for Generalizable Face Forgery Detection.” Proceedings of the Computer Vision and Pattern Recognition Conference, 19207–17.
Han, Zeyu, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. 2024. “Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey.” Transactions on Machine Learning Research.
Hu, Edward J, Phillip Wallis, Zeyuan Allen-Zhu, et al. 2022. “LoRA: Low-Rank Adaptation of Large Language Models.” International Conference on Learning Representations.
Livernoche, Victor, Akshatha Arodi, Andreea Musulan, et al. 2025. “OpenFake: An Open Dataset and Platform Toward Real-World Deepfake Detection.” arXiv Preprint arXiv:2509.09495.
Ni, Yunsheng, Depu Meng, Changqian Yu, Chengbin Quan, Dongchun Ren, and Youjian Zhao. 2022. “Core: Consistent Representation Learning for Face Forgery Detection.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12–21.
Qian, Yuyang, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. 2020. “Thinking in Frequency: Face Forgery Detection by Mining Frequency-Aware Clues.” European Conference on Computer Vision, 86–103.
Radford, Alec, Jong Wook Kim, Chris Hallacy, et al. 2021. “Learning Transferable Visual Models from Natural Language Supervision.” International Conference on Machine Learning, 8748–63.
Rossler, Andreas, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. 2019. “Faceforensics++: Learning to Detect Manipulated Facial Images.” Proceedings of the IEEE/CVF International Conference on Computer Vision, 1–11.
Yan, Zhiyuan, Jiangming Wang, Peng Jin, et al. 2025. “Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection.” International Conference on Machine Learning, 70268–88.
Yan, Zhiyuan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. 2023. “Ucf: Uncovering Common Features for Generalizable Deepfake Detection.” Proceedings of the IEEE/CVF International Conference on Computer Vision, 22412–23.
Yermakov, Andrii, Jan Cech, Jiri Matas, and Mario Fritz. 2026. “Deepfake Detection That Generalizes Across Benchmarks.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 773–83.